Inference Engineering
[github][github][github][github][github][github][github][github] inference-engineeringllm-inferencegenerative-aigpu-optimizationmodel-servingproduction-ml
Inference Engineering
Authors: Philip Kiely Year: 2026 Tags: llm-inference, model-serving, gpu-optimization, production-ml, generative-ai, inference-engineering
TL;DR
A practitioner's book covering the full stack of deploying generative AI models in production, from CUDA kernels and GPU memory hierarchies through multi-cloud autoscaling. Targets engineers transitioning from closed-model APIs to self-hosted open models who must optimize for latency, cost, and reliability without sacrificing quality.
First pass — the five C's
Category. Practitioner guide / survey synthesis — not a research paper. Presents no novel experimental results; instead consolidates existing techniques and engineering practice.
Context. AI inference serving sub-field. Builds on: Vaswani et al. "Attention Is All You Need" (transformer architecture foundation); vLLM and SGLang (inference engine design); FlashAttention (attention kernel optimization); DeepSeek R1/V3 (open-model quality parity milestone). Situates itself against the backdrop of the post-ChatGPT open-model explosion and the Hugging Face ecosystem.
Correctness. Load-bearing assumptions: (1) open models are now quality-competitive with closed models — supported anecdotally by DeepSeek V3/R1 (Dec 2024 / Jan 2025) but asserted as settled; (2) dedicated inference is economically superior at scale — plausible but the crossover threshold is not quantified; (3) the runtime/infrastructure/tooling tripartite decomposition cleanly covers the problem space — reasonable framing but not derived from first principles.
Contributions. - Unified conceptual framework decomposing inference into three layers: runtime (per-instance optimization), infrastructure (multi-cluster scaling), and tooling (developer abstraction). - Practical decision trees for model selection, online-vs.-offline workloads, and consumer-vs.-B2B latency/cost tradeoffs. - Breadth-first survey of optimization techniques (quantization, speculative decoding, KV cache reuse, tensor parallelism, disaggregation) applied across multiple modalities beyond LLMs. - Production operations chapter covering autoscaling, cold starts, multi-cloud capacity management, zero-downtime deployment, and cost estimation.
Clarity. Prose is consistently accessible and well-organized, with functional analogies (NFL athletes, sports coaches); occasionally slides into promotional language about Baseten and its customers.
Second pass — content
Main thrust: Serving open generative AI models in production at scale requires co-optimizing three interdependent layers — runtime performance (kernels, inference engines, quantization), infrastructure (autoscaling, multi-cloud routing), and developer tooling — and the best entry point is choosing the smallest model that passes task-specific evals before applying any other optimization.
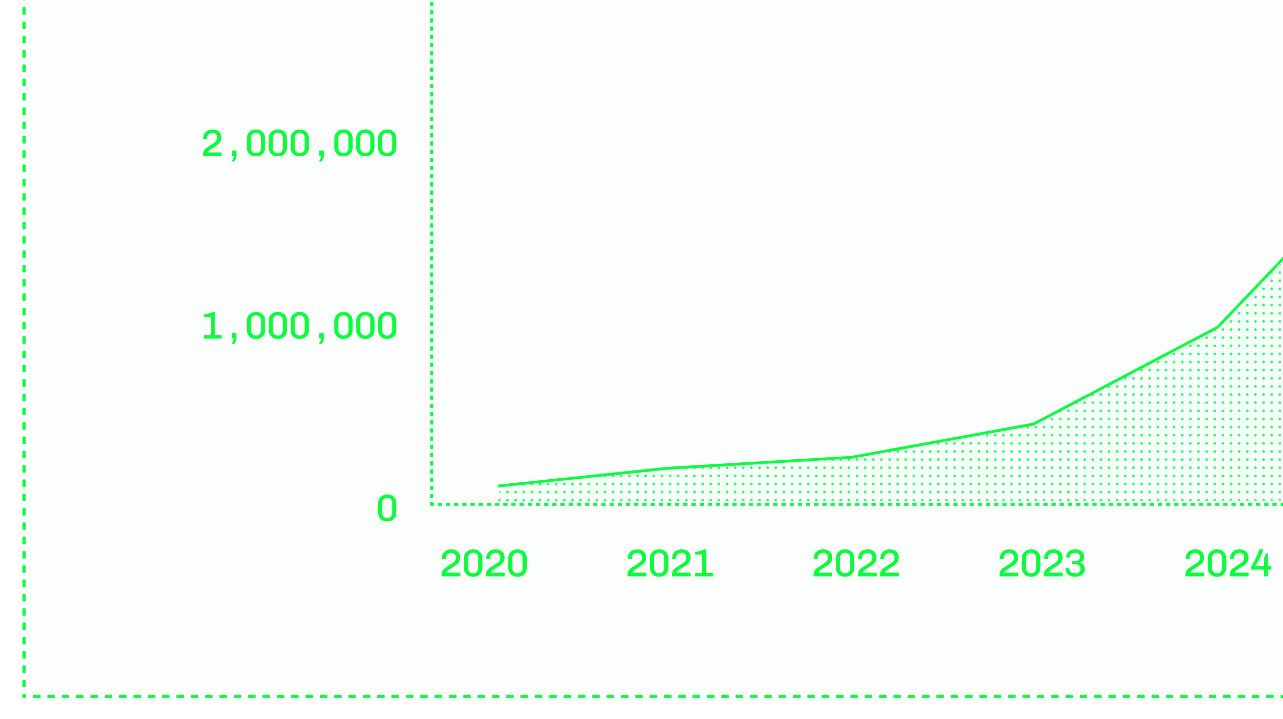
Supporting evidence: - Open models claimed to be "at least 80% less expensive" than closed APIs at scale; no methodology or conditions specified. - Dedicated deployments asserted to achieve "four nines or better" uptime vs. "two nines" for closed-model APIs; no source cited. - DeepSeek R1 (671B parameters, Jan 2025) released with distilled variants on Llama 3 and Qwen 2.5 architectures; presented as the moment open-model quality parity was achieved. - Hugging Face hosts over 2 million open models as of writing, 25× more than five years prior (Figure P.1). - Text-to-SQL fine-tuning example: task-specific fine-tuning reduces required model size from hundreds of billions to a few billion parameters for equivalent task performance. - LLM latency metrics defined: TTFT (prefill-bound), perceived TPS / inter-token latency (decode-bound, bandwidth-bound); P50/P90/P95/P99 percentile framing advocated over mean latency.
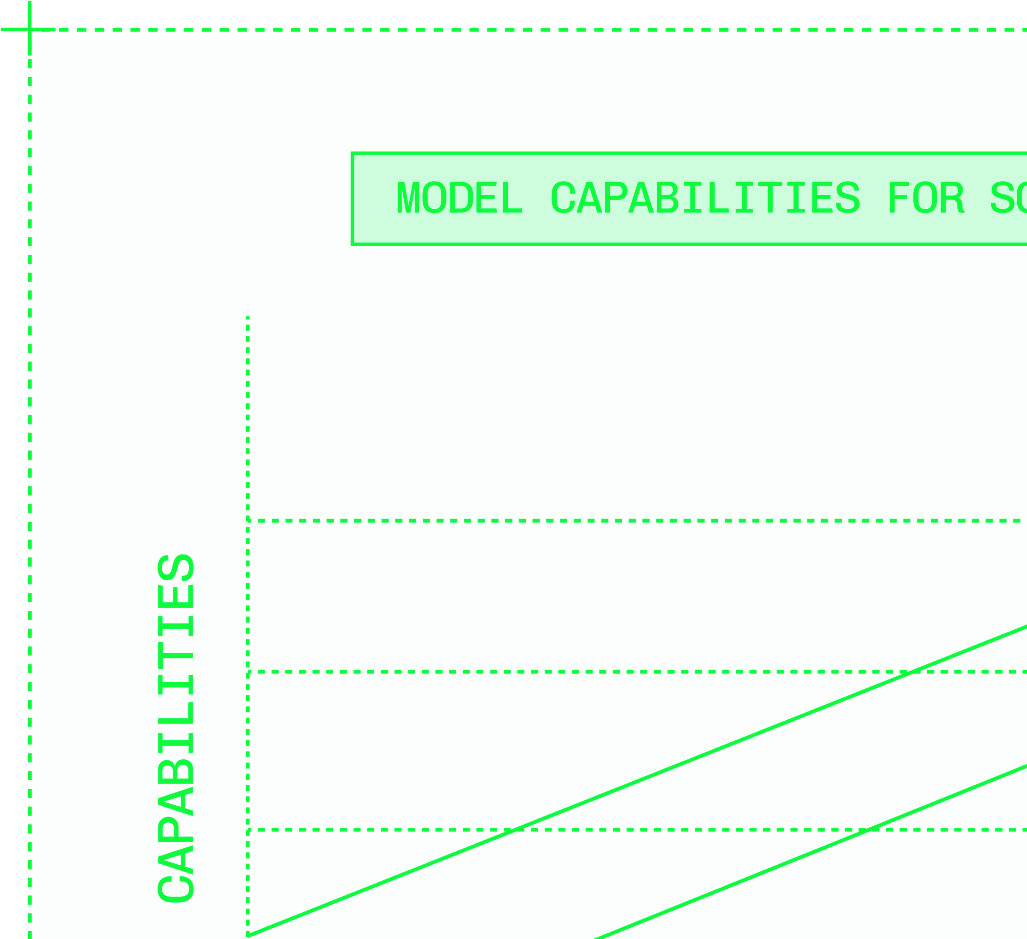
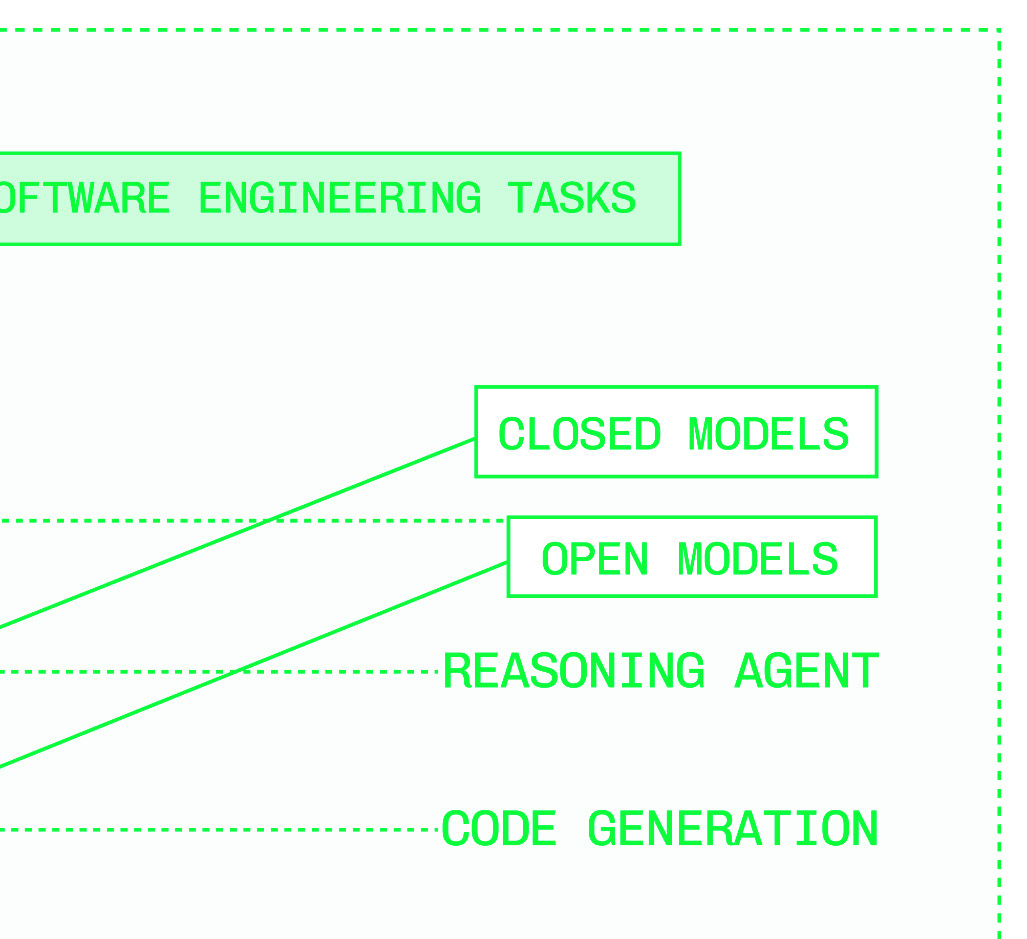
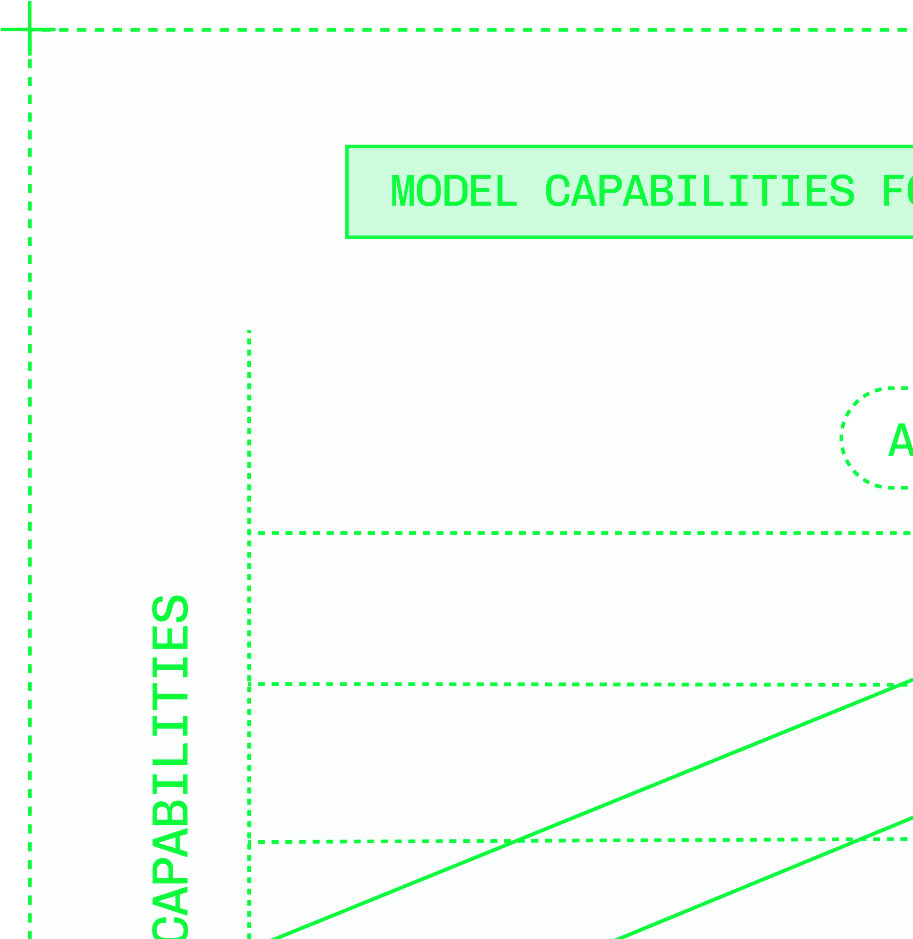
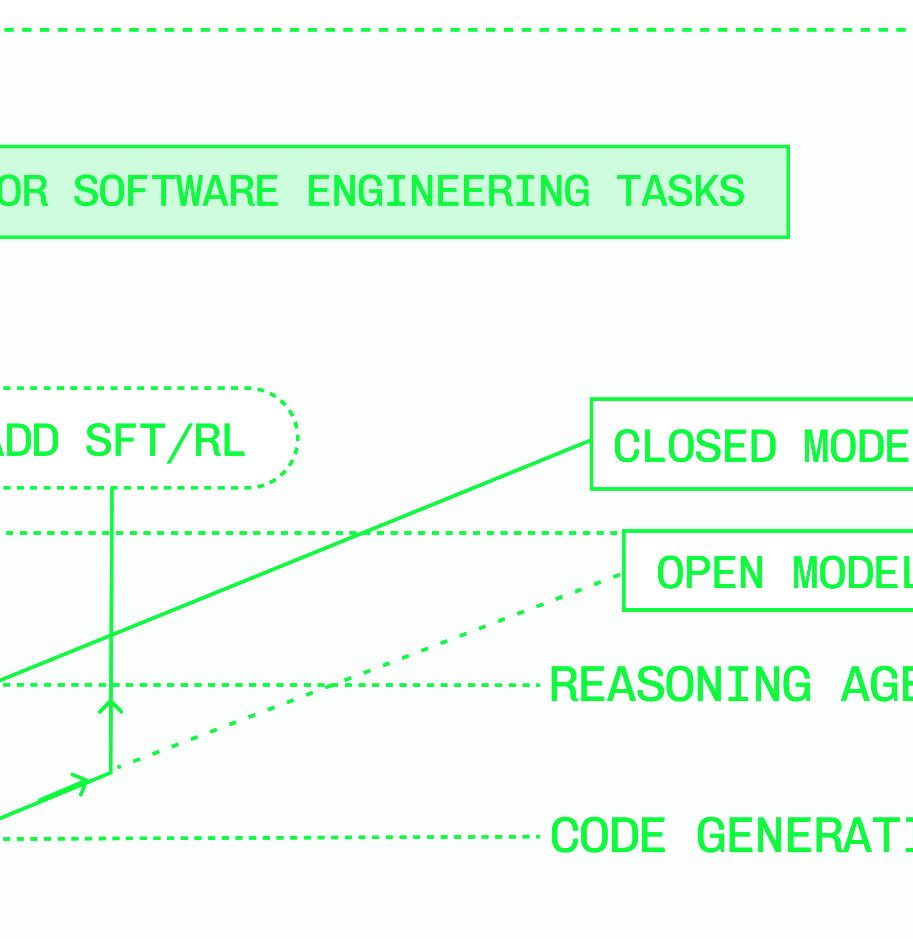
Figures & tables: Figures P.1–P.3 (model growth curves, capability curves, customization value prop), Figures 0.1–0.3 (inference stack, speculation diagram, multi-cloud capacity diagram), Figures 1.1–1.5 (latency distribution, TTFT/TPS illustration), Figures 2.1–2.6 (matmul, activation functions, tokenization, decode logit selection). No axes labels, error bars, confidence intervals, or statistical significance reported — consistent with a practitioner book but means no claim is empirically validated. The latency distribution figure (1.5) illustrating right-skew is conceptual, not data-derived.
Follow-up references: - Vaswani et al., "Attention Is All You Need" — foundational transformer architecture underlying all techniques discussed. - vLLM project documentation/paper — most heavily referenced inference engine; disaggregation and PagedAttention details. - DeepSeek R1 technical report — primary case study for open-model quality parity and distillation at scale. - Appendix B (Recommended Reading) within the book itself — curated list across architecture, GPU infrastructure, inference optimization research, and evals tooling (not fully reproduced in the excerpt provided).
Third pass — critique
Implicit assumptions: - NVIDIA GPU ecosystem dominance is treated as given; AMD, Intel Gaudi, and custom ASICs receive only a brief survey section — results may not generalize to non-NVIDIA stacks. - Open-weight licensing stability is assumed; the book notes license heterogeneity but does not analyze IP or legal risk, which can break deployment decisions. - The "80% cost reduction" and uptime figures are stated as facts; if workload, model size, or traffic pattern assumptions underlying these numbers differ from a reader's context, the economics case for dedicated inference may not hold. - Quality parity between open and closed models is asserted as durable based on a single data point (DeepSeek, late 2024); this assumption would break if frontier closed models re-open the gap.
Missing context or citations: - No engagement with academic inference literature: Orca (continuous batching), Sarathi (chunked prefill), SpotServe (spot-instance inference), or DejaVu (sparse attention at inference time) are absent despite being directly relevant. - No independent comparison of inference providers; Baseten is the author's employer and is positioned favorably throughout without competitive benchmarking. - Security and adversarial robustness of open-weight deployments (model extraction, prompt injection at scale) are mentioned only briefly under compliance, without substantive treatment. - The "Goodhart's Law applies to benchmarks" point is made without citing the growing literature on benchmark contamination and evaluation methodology.
Possible experimental / analytical issues: - Every quantitative claim (80% cost, two vs. four nines, 25× model growth) appears without methodology, sample, or source — readers should not treat these as validated benchmarks. - The text-to-SQL fine-tuning example is illustrative but presented as representative of what fine-tuning can achieve; no data on how often such dramatic size reductions are possible in other domains. - Authored by a Baseten employee and published by Baseten Books; tooling recommendations (vLLM, SGLang, TensorRT-LLM, NVIDIA Dynamo, Baseten) and customer examples are not independently verified, creating selection and framing bias. - Knowledge cutoff of January 2026 is acknowledged, but the field moves fast enough that specific engine comparisons and hardware specs (Blackwell, Rubin) may already be outdated for readers in 2026 or later.
Ideas for future work: - Reproducible head-to-head benchmark of vLLM vs. SGLang vs. TensorRT-LLM on identical model/workload combinations with disclosed hardware, ISL/OSL distributions, and concurrency levels. - Quantitative analysis of the shared→dedicated inference economic crossover as a function of model size, tokens-per-request distribution, and traffic volume — to replace the unsourced 80% claim with a decision framework. - Extension to non-transformer architectures (Mamba/SSM, RWKV) whose inference profiles differ fundamentally from attention-based models and are absent from the book. - Adversarial threat model for open-weight production deployments: model extraction via API, membership inference, and jailbreak surface area introduced by self-hosting vs. managed APIs.
Figures from the paper












Methods
- quantization
- speculative decoding
- KV cache reuse
- prefix caching
- model parallelism
- tensor parallelism
- disaggregation
- FlashAttention
- fine-tuning
- distillation
- continuous batching
- kernel fusion
Claims
- Inference engineering requires three cooperating layers — runtime optimization, infrastructure scaling, and developer tooling — to achieve mission-critical production serving of generative AI models.
- The gap in intelligence between open and closed models effectively closed with the release of DeepSeek V3 and R1 in December 2024, making open-model inference engineering a viable strategy for all AI product builders.
- Dedicated deployments of open models can be at least 80 percent less expensive than shared pay-per-token APIs at scale, while also enabling higher availability and lower latency.
- Model selection is the single most impactful performance optimization decision, as a smaller fine-tuned model that passes domain-specific evals will always be faster and cheaper than a larger general-purpose model.
- LLM inference consists of two distinct phases — compute-bound prefill and bandwidth-bound decode — whose different bottlenecks motivate techniques such as disaggregation, speculative decoding, and KV cache reuse.