XGBoost: A Scalable Tree Boosting System
[arxiv] [github][github] gradient-boostingtree-ensemblescalable-machine-learningdistributed-computingsparse-data
XGBoost: A Scalable Tree Boosting System
Authors: Tianqi Chen, Carlos Guestrin Year: 2016 Tags: gradient-boosting, decision-trees, scalable-ml, sparse-data, distributed-systems, approximate-algorithms
TL;DR
XGBoost is an end-to-end gradient tree boosting system that combines a novel sparsity-aware split-finding algorithm, a theoretically justified weighted quantile sketch for approximate learning, and hardware-level systems optimizations (cache-aware prefetching, block compression, disk sharding) to scale to 1.7 billion examples on minimal cluster resources. It ran on every top-10 KDDCup 2015 winning team and in 17 of 29 Kaggle winning solutions in 2015, making it the empirically dominant ensemble method of its era.
First pass — the five C's
Category. Research prototype / systems paper with algorithmic contributions.
Context. Gradient tree boosting subfield. Builds directly on Friedman 2001 (gradient boosting machine), Friedman, Hastie & Tibshirani 2000 (second-order additive logistic regression / scoring derivation), Tyree et al. 2011 (pGBRT — main parallel baseline), and Zhang & Johnson 2014 (regularized greedy forest — prior regularized tree objective).
Correctness. Load-bearing assumptions: (1) second-order Taylor expansion adequately approximates arbitrary differentiable loss — breaks for highly non-quadratic losses; (2) second-order gradient statistics hi are non-negative, i.e., loss is strictly convex — required for hi to function as instance weights in the quantile sketch; (3) one-time sort cost is amortizable across training iterations — reasonable for many-tree ensembles. All three appear plausible within the paper's scope.
Contributions. - Novel sparsity-aware split-finding that learns optimal default directions for missing values and runs in O(∥x∥₀) time, achieving ~50× speedup over a naive implementation on sparse data. - Theoretically justified weighted quantile sketch with provable ε-approximation guarantees, merge and prune operations — the first such algorithm for weighted datasets. - Cache-aware prefetching via internal gradient-statistics buffers, delivering ~2× speedup on 10M-instance datasets versus naive block access. - Out-of-core computation through column-block compression (26–29% compression ratio) and multi-disk sharding, enabling 1.7B example training on a single machine and 4-machine clusters.
Clarity. Well-organized with clear pseudocode (Algorithms 1–4) and per-optimization microbenchmarks; the appendix proof for the weighted quantile sketch is rigorous but dense; Table 1's "partially" label for sparsity support across competing systems is used without a definition.
Second pass — content
Main thrust: XGBoost achieves >10× single-machine speedup over scikit-learn's exact greedy implementation and outperforms distributed in-memory systems (Spark MLLib, H2O) on the 1.7B-row Criteo dataset by coupling algorithmic improvements (sparsity awareness, weighted quantile sketch) with systems engineering (pre-sorted column blocks, cache prefetching, disk-based out-of-core).
Supporting evidence: - Higgs-1M, 500 trees, exact greedy: XGBoost 0.6841 sec/tree, AUC 0.8304 vs. scikit-learn 28.51 sec/tree, AUC 0.8302; R GBM 1.032 sec/tree, AUC 0.6224 (different expansion strategy). - Yahoo LTRC, 500 trees: XGBoost 0.826 sec/tree, NDCG@10 0.7892 vs. pGBRT 2.576 sec/tree, NDCG@10 0.7915. - Sparsity-aware algorithm on Allstate-10K: >50× faster than naive across all thread counts. - Cache-aware prefetching on Allstate-10M and Higgs-10M: ~2× speedup; effect negligible on 1M-instance datasets (gradient stats fit in cache). - Out-of-core on Criteo subsets (AWS c3.8xlarge, 32 vCores, 2×320 GB SSD, 60 GB RAM): block compression alone gives 3× speedup; adding two-disk sharding gives additional 2× speedup; combined method processes full 1.7B examples. - Distributed on 32 EC2 m3.2xlarge nodes: XGBoost >10× faster per iteration than Spark MLLib; ~2.2× faster per iteration than H2O; scales to full 1.7B with 4 machines; near-linear (slightly super-linear due to file-cache growth) scaling from 4 to 32 machines.
Figures & tables: Figs. 5, 7, 10–13 carry the performance argument; all use log-log axes with labels. No figure shows error bars, confidence intervals, or reports statistical significance — all timing results appear to be single runs. Fig. 3 shows AUC vs. iteration curves for approximate vs. exact greedy, axes labeled, no variance shown. Table 1 is a qualitative feature matrix; "partially" is undefined. Table 3 and 4 report single-run times and single evaluation-set accuracy scores with no variance. Visualization is functional but statistical rigor is absent throughout.
Follow-up references: - Friedman 2001 (Greedy function approximation) — foundational theory for gradient boosting and scoring function derivation used throughout. - Tyree et al. 2011 (pGBRT) — primary parallel baseline; understanding its limitations motivates XGBoost's design. - Greenwald & Khanna 2001 (GK quantile sketch, SIGMOD) — classical unweighted algorithm that the weighted quantile sketch extends. - Zhang & Johnson 2014 (Regularized greedy forest, IEEE TPAMI) — prior regularized tree objective that XGBoost's regularization resembles but simplifies.
Third pass — critique
Implicit assumptions: - hi > 0 everywhere is required for the weighted quantile sketch to be valid (hi is the instance weight); non-convex or piecewise losses can produce zero or negative second derivatives, breaking the sketch's theoretical guarantees. - The ~50× sparsity speedup is measured exclusively on data sparse due to one-hot encoding; the benefit is proportional to the fraction of missing entries and may be far smaller for dense data with moderate missingness. - Cache benefits (Fig. 7) are architecture-specific: the crossover point between cache-aware and naive depends on L2/L3 cache size and memory bandwidth of the specific CPU, which is not characterized. - The 26–29% compression ratio implicitly assumes that the "general purpose" compression algorithm (unnamed in the paper) performs comparably across feature distributions — not validated on diverse data types.
Missing context or citations: - No comparison against LightGBM-style histogram boosting (published concurrently by Microsoft Research; may postdate submission, but the absence limits long-term positioning). - PLANET (Panda et al. 2009, VLDB) is cited but not included in distributed experiments despite being a dedicated distributed tree system. - The "17 of 29 Kaggle winners" claim is sourced from blog posts, not a reproducible audit; no definition of "winning solution" (top-1? top-3?) is given consistently. - No evaluation on regression tasks: all headline benchmarks are binary classification or ranking, leaving generalization to regression undemonstrated.
Possible experimental / analytical issues: - Zero statistical replication: all timing numbers appear to be single-run point estimates; variance from OS scheduling, memory contention, and I/O jitter is ignored. - Higgs-1M is used for single-machine comparison specifically because scikit-learn cannot complete on larger subsets in reasonable time — the dataset size is chosen to accommodate the weakest baseline, not to stress-test XGBoost. - R GBM comparison is explicitly noted to use a different (single-branch) tree expansion, making the AUC comparison (0.8304 vs. 0.6224) misleading as a quality benchmark; it should be presented separately from speed comparisons. - Criteo preprocessing (replacing 26 ID features with count/CTR statistics) is a non-trivial feature engineering step that is not ablated; the results are entangled with this choice rather than reflecting raw system capability. - The distributed comparison uses only Spark MLLib and H2O — both general-purpose in-memory frameworks rather than specialized tree boosting systems — as baselines, which may understate competition. - Linear scaling claim (Fig. 13) is described by the authors as "slightly super-linear" due to file-cache accumulation with more machines, undermining the scaling narrative.
Ideas for future work: 1. Evaluate the weighted quantile sketch under non-convex losses (e.g., focal loss, custom objectives with regions of negative curvature) and quantify the approximation error when hi ≤ 0 for a subset of instances. 2. Direct head-to-head benchmarking against LightGBM on identical hardware and datasets, explicitly trading off histogram-based vs. sorted-column approaches for varying dataset densities and depths. 3. Adaptive block sizing that profiles available CPU cache at runtime and adjusts the block size dynamically, rather than relying on the fixed empirical choice of 2¹⁶ rows. 4. Replicated timing experiments (≥30 runs) with reported mean and standard deviation to establish whether observed speedup factors (2×, 3×, 50×) are statistically distinguishable from noise.
Figures from the paper
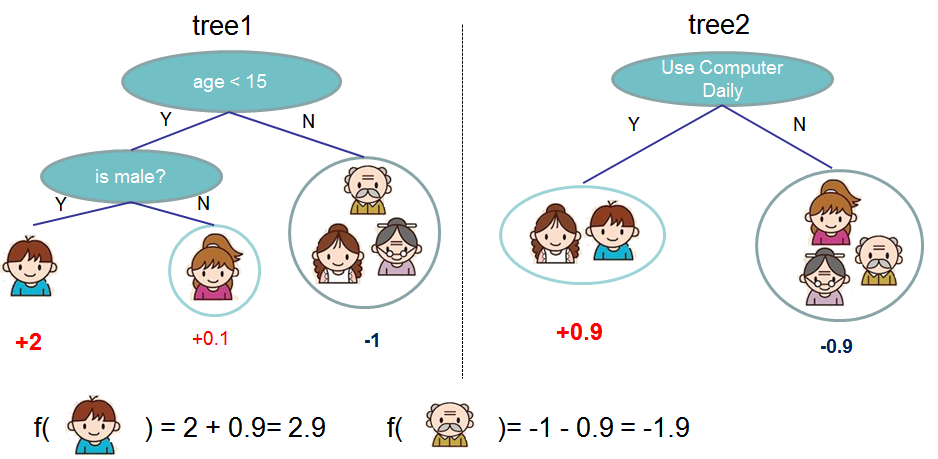

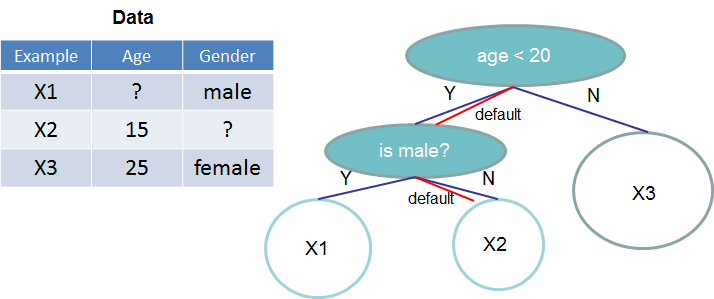
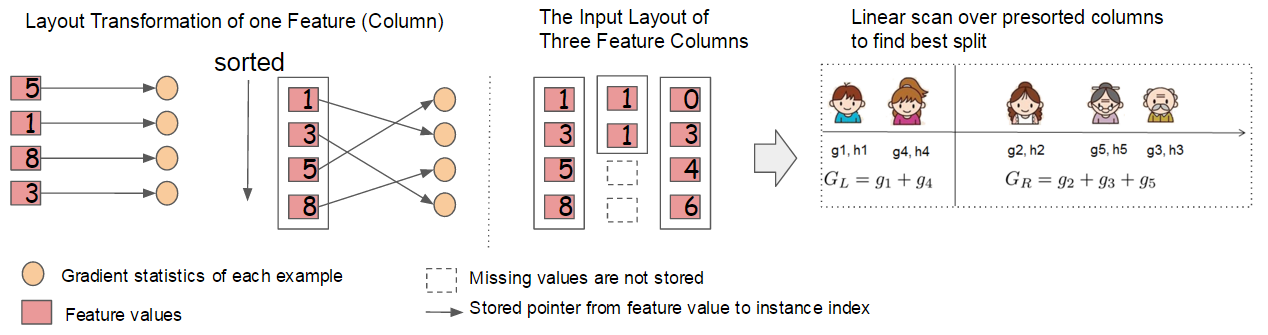
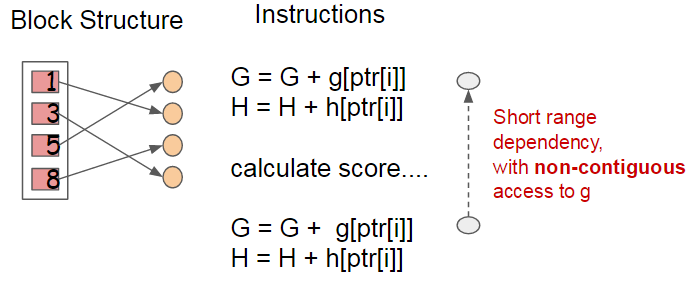
Methods
- gradient tree boosting
- exact greedy split finding
- approximate split finding
- weighted quantile sketch
- sparsity-aware split finding
- cache-aware prefetching
- column block structure
- out-of-core computation
- block compression
- block sharding
- column subsampling
- second-order gradient approximation
Datasets
- Allstate insurance claim dataset
- Higgs Boson dataset
- Yahoo! Learning to Rank Challenge dataset
- Criteo terabyte click log dataset
Claims
- XGBoost runs more than ten times faster than existing popular single-machine tree boosting solutions such as scikit-learn.
- A novel sparsity-aware algorithm reduces computation complexity to be linear in the number of non-missing entries and runs 50x faster than a naive implementation on sparse data.
- A theoretically justified weighted quantile sketch enables approximate tree learning with instance weights and provable accuracy guarantees.
- XGBoost scales to 1.7 billion examples on a single machine via out-of-core computation using block compression and sharding.
- XGBoost outperforms distributed systems Spark MLLib and H2O in both speed and scalability, handling the full 1.7 billion example Criteo dataset with as few as four machines.