High-Dimensional Data Analysis with Low-Dimensional Models: Principles, Computation, and Applications
[github] sparse-recoverylow-rank-modelscompressed-sensingconvex-optimizationhigh-dimensional-statisticsdeep-learning
High-Dimensional Data Analysis with Low-Dimensional Models: Principles, Computation, and Applications
Authors: John Wright, Yi Ma Year: 2018 (copyright; preface dated December 2020; Cambridge University Press pre-publication) Tags: sparse-recovery, low-rank-models, compressed-sensing, convex-optimization, nonconvex-optimization, high-dimensional-statistics
TL;DR
Graduate textbook unifying the theory of sparse and low-rank models, scalable convex and nonconvex optimization algorithms, and applications spanning MRI, wideband spectrum sensing, face recognition, and deep networks. Positioned as bridging the gap between mathematical principles and real-world deployment—a gap left by existing theory-only treatments.
First pass — the five C's
Category. Graduate textbook / comprehensive survey of a research field.
Context. Builds on: Candès & Tao (compressive sensing and error correction), Donoho (high-dimensional data analysis and sparse coding), Vidal, Ma & Sastry [VMS16] (Generalized PCA / subspace mixtures), and Van den Berg / Wainwright / Foucart & Rauhut [FR13, HTW15, Van16, Wai19] (existing sparse/low-rank theory texts). Situates itself as the first to systematically couple that theory with scalable computation and domain-specific applications.
Correctness. Load-bearing assumptions: (1) real-world high-dimensional data genuinely lies near sparse or low-rank manifolds; (2) convex relaxations (ℓ₁, nuclear norm) succeed under RIP or incoherence conditions derivable in practice; (3) nonconvex landscapes for problems with sufficient symmetry (rotational or discrete) are benign enough for gradient-based methods. All three are supported by the field's established results, though assumption (3) is presented as an active research frontier.
Contributions. - Unified three-part pedagogical architecture (Principles → Computation → Applications) covering sparse models, low-rank models, robust PCA, and general atomic-norm models under one framework. - Systematic treatment of both convex (proximal gradient, ADMM, ALM, Frank-Wolfe) and nonconvex (cubic regularization, negative-curvature descent, generalized power iteration) large-scale optimization methods alongside recovery theory. - Seven application chapters that explicitly model domain non-idealities (nonlinearity, occlusion, sensor physics) rather than treating applications as afterthoughts. - Final chapter (Ch. 16) deriving deep network architectures from a "Maximal Coding Rate Reduction" principle, connecting sparse/low-rank theory to deep learning.
Clarity. Writing is exceptionally clear and candid; the preface explicitly acknowledges application-chapter bias toward the authors' own research, and the dependency chart (Fig. 0.4) gives instructors concrete course-design guidance. The foreword by Candès is an unusually informative orientating essay.
Second pass — content
Main thrust: Sparse and low-rank structure—formalized via ℓ₁ and nuclear-norm minimization with RIP/incoherence guarantees—is both mathematically tractable and computationally scalable, enabling high-quality signal recovery from severely undersampled or corrupted measurements; seven real application domains confirm this translates to practice.
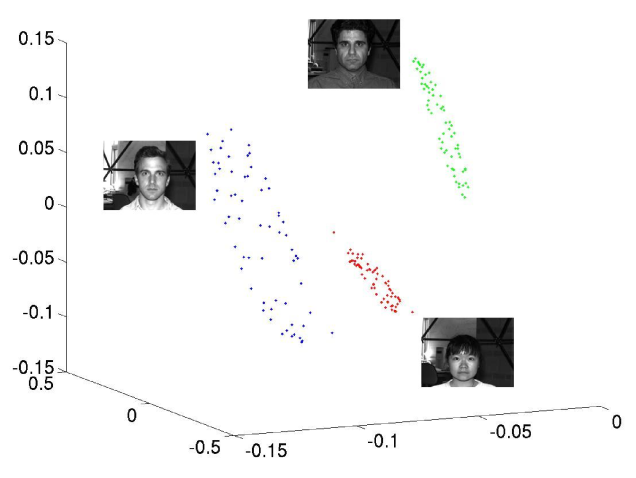
Supporting evidence: - Nyquist-Shannon theorem introduced as a baseline; compressive sensing claimed to enable MRI reconstruction "ten times faster" than Nyquist-rate scanning (foreword; chapter 10 develops the physics and algorithms). - Face recognition (Ch. 13) formulated as sparse representation over a gallery dictionary; dense occlusion handled via "Cross and Bouquet" construction. - Matrix completion (Ch. 4) guarantees: nuclear-norm minimization recovers rank-r matrices from O(rn log n) random entries under incoherence; noisy and approximate-rank extensions included. - Robust PCA (Ch. 5) via Principal Component Pursuit: simultaneous recovery of low-rank and sparse components under conditions on coherence and sparsity fraction. - Phase transition results (Ch. 3, 6) give sharp sample-complexity thresholds for ℓ₁ recovery using statistical dimension of descent cones and the kinematic formula. - Rate Reduction principle (Ch. 16): experiments on real data support that maximizing coding rate reduction produces discriminative representations; exact numbers not visible in the provided front matter.
Figures & tables: Only front-matter figures are in the provided text. Fig. 0.1 (2500×2500 vs 250×250 image) illustrates information redundancy; no axes needed. Fig. 0.2 (group photo) is illustrative only. Fig. 0.3 (collaborative filtering matrix) is a schematic. Fig. 0.4 (chapter dependency graph) is the most informative: color-coded routes (red/blue/green/orange) map four distinct course tracks clearly. No error bars or statistical significance appear in front matter; whether they appear in application chapters cannot be assessed from provided text.
Follow-up references: - Candès & Tao (compressive sensing / error correction) — foundational papers the theory chapters are built upon. - Foucart & Rauhut [FR13] — complementary theory-only reference for readers wanting deeper RIP proofs. - Wainwright [Wai19] — statistical treatment of high-dimensional problems for the statistics-leaning reader. - Vidal, Ma & Sastry [VMS16] (GPCA) — predecessor work on subspace mixtures; Ch. 16 claims an unexpected connection via lossy coding rates.
Third pass — critique
Implicit assumptions: - Low-dimensional structure (sparsity or low rank) is assumed to be the correct model; for data that is approximately but not truly low-dimensional, recovery guarantees degrade in ways that are acknowledged for sparse and low-rank cases but less fully explored for the general atomic-norm setting (Ch. 6). - RIP of Gaussian random matrices is the canonical proof vehicle; structured measurement matrices (Fourier subsampling, single-pixel camera) require separate arguments that may not achieve identical constants—practical implications are noted but not uniformly quantified. - Nonconvex landscapes of Ch. 7 are claimed to be benign under rotational or discrete symmetry, but the provided taxonomy is not exhaustive; the result breaks for problems outside these symmetry classes, which is acknowledged only briefly as "open problems." - The connection between sparse/low-rank models and deep networks in Ch. 16 rests on the "Maximal Coding Rate Reduction" principle, whose theoretical guarantees (manifold classification) are described as a minimal case (two 1D submanifolds); generalization to the architectures used in practice is presented as a conjecture, not a theorem.
Missing context or citations: - No engagement in the provided text with adversarial robustness literature, which is relevant to the face recognition and image processing applications. - Tensor decomposition methods are mentioned (Ch. 6.3.2) as intractable for convex relaxation but no alternative tensor methods (e.g., tensor train, HOSVD) are cited or compared. - Deep learning textbooks (e.g., Goodfellow, Bengio & Courville) are not cited for context; the relationship to the statistical learning theory tradition (VC dimension, PAC learning) is not discussed. - Distributed and federated optimization settings are absent, despite the book's stated motivation of "unprecedented scale."
Possible experimental / analytical issues: - Application chapters are self-admittedly "biased by the authors' own expertise"; competing methods are not systematically benchmarked against the proposed algorithms in the provided content. - Quantitative experimental results in Ch. 16 (rate reduction experiments on "real data") are referenced but not visible in the provided text; reproducibility and dataset details cannot be verified. - The MRI "ten times faster" claim appears only in the foreword (attributed to general field progress), not as a controlled experiment result attributable to specific algorithms in the book. - Phase transition plots (Ch. 3, 6) present sharp thresholds, but the statistical significance of empirical phase transitions versus the theoretical predictions is not discussed in the front matter.
Ideas for future work: - Extend the rate reduction / deep network connection (Ch. 16) to transformers and attention mechanisms, which are the dominant architecture post-2020 and absent from the book. - Develop joint sparsity-and-low-rank recovery guarantees for tensor data, filling the gap left by the noted intractability of convex tensor relaxations. - Provide end-to-end sample complexity bounds for the application pipelines (e.g., photometric stereo + robust PCA + shape recovery) rather than bounding each module independently. - Empirically and theoretically characterize when the benign nonconvex landscape of Ch. 7 fails—i.e., derive conditions under which symmetry-exploiting gradient methods get trapped—to bound the scope of the nonconvex theory.
Figures from the paper



















Methods
- l1 minimization
- nuclear norm minimization
- principal component pursuit
- proximal gradient methods
- augmented Lagrange multipliers
- alternating direction method of multipliers
- restricted isometry property
- singular value decomposition
- nonconvex optimization
- generalized power iteration
- stochastic gradient descent
- Frank-Wolfe method
Claims
- Sparse and low-rank models provide a unifying mathematical framework for recovering low-dimensional structure from high-dimensional data across a wide range of applications.
- Convex relaxations such as l1 minimization and nuclear norm minimization provably recover sparse and low-rank signals under appropriate conditions characterized by the restricted isometry property and incoherence.
- First-order optimization methods (proximal gradient, ADMM, Frank-Wolfe) can solve large-scale structured recovery problems efficiently and scalably.
- Nonconvex formulations with rotational or discrete symmetries admit benign global geometry that allows gradient-based methods to find global optima.
- The principles of sparse and low-rank modeling shed light on the design and theoretical understanding of deep neural networks.